On-device AI
Speech processing always runs on your Mac: audio capture, transcription (Parakeet), speaker identification, echo cancellation, and voice detection. No setup, no plan requirement — audio never leaves the machine.
The AI features that work on transcript text — summaries, the live assistant, dictation cleanup, transform — default to Google Gemini through our open-source proxy. This page is about running those on your own hardware instead. Three levels, in increasing order of setup:
| You want | Use | Covers |
|---|---|---|
| No AI at all | Local Mode | Transcription and speakers only; every AI feature off |
| Typing features on-device, zero setup | Apple (On-Device) | Dictation, Transform |
| Every AI feature on your hardware | Custom endpoint → a local server | Dictation, Transform, summaries, live assistant |
Apple (On-Device): dictation and transform
On macOS 26 with Apple Intelligence enabled, MimicScribe can run Dictation and Transform on Apple’s built-in on-device model. Nothing to install, nothing to configure.
Open Settings → AI Provider, and under Feature routing set Dictation or Transform to Apple (On-Device). The option only appears on Macs where the model is available.
Apple’s model has a small context window — a full meeting transcript doesn’t fit — so it’s offered only for the typing features. For summaries and the live assistant, use a local server below.
A local server: every feature
Any server that speaks the OpenAI chat-completions API works. Ollama is the shortest path:
Install Ollama and pull a model:
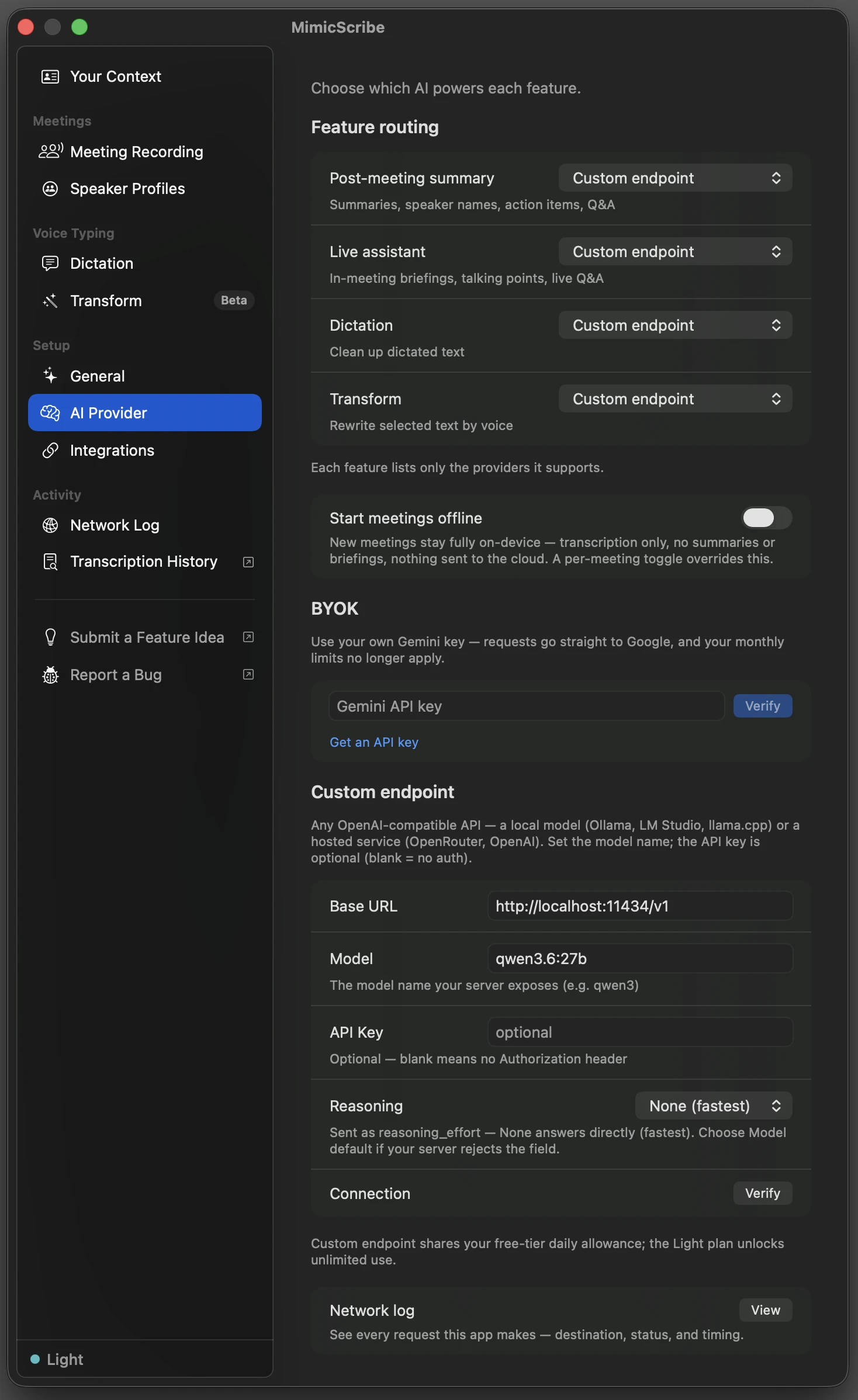
ollama pull qwen3In Settings → AI Provider, under Custom endpoint, fill in:
- Base URL —
http://localhost:11434/v1 - Model — the name you pulled, e.g.
qwen3.6:27b - API Key — leave blank
- Reasoning — leave at None. Thinking models (like Qwen) otherwise spend minutes on hidden reasoning before every answer.
Click Verify. It checks the server is reachable, then sends a tiny request to confirm the model actually responds.
- Base URL —
Under Feature routing, set the features you want to Custom endpoint. You can mix — summaries on your local model, dictation on Gemini.
LM Studio and llama.cpp work the same way; only the Base URL and model name change. The full reference — what routes where, plan limits, troubleshooting — is on the Custom AI Endpoint page.
What to expect
Own hardware means owning the quality tradeoff:
- Quality is the model you pick. MimicScribe’s prompts are tuned against Gemini. Dictation and transform are short, focused tasks that mid-size local models handle; meeting summarization is a long-context task — use the largest model your Mac runs comfortably.
- A few things stay on the default Gemini path: reference-document search, vocabulary spelling hints, and image (OCR) processing. They rely on capabilities a general chat endpoint doesn’t reliably provide, and each fires only if you use the feature it serves.
- Free-tier caps still apply. A custom endpoint shares the same per-feature daily allowance as the default path — a product limit, not a cost one. Light and Unlimited lift it.
Watch it work
Open Settings → Network Log and run a meeting or a dictation. Each AI request lists where it went — with a local server, that’s your own machine:
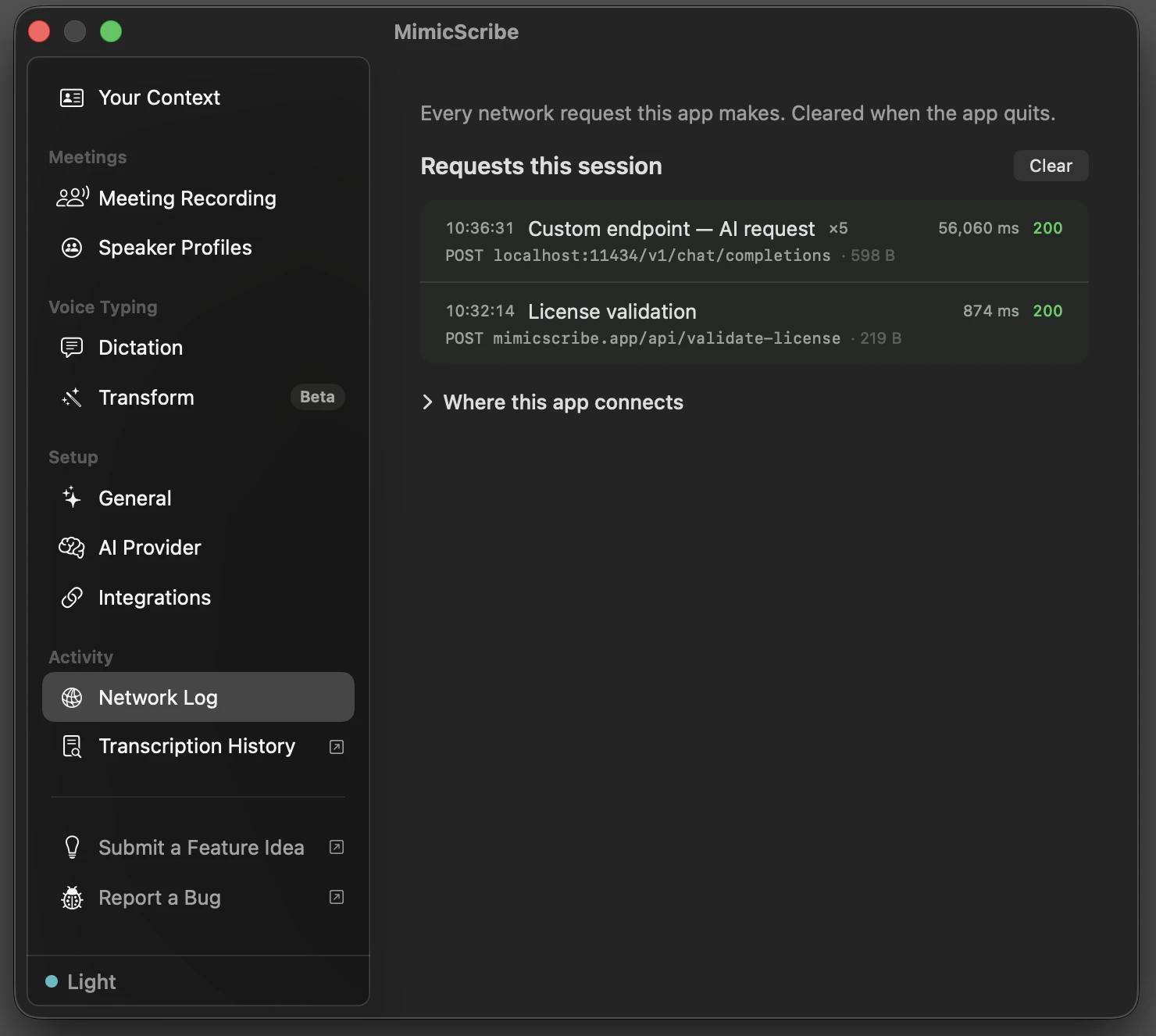
Network Activity documents what the log records and how to verify it from outside the app with nettop or Little Snitch.
Local Mode: no AI at all
Routing changes where the AI runs. Local Mode is different — it turns AI off entirely for a meeting: transcription and speaker separation only, nothing sent anywhere, no summaries to backfill until you choose to. Toggle it per meeting when you start one, or set Start meetings offline in Settings → AI Provider to make it the default. Details in Privacy & Data.